AlExperiment
alipy.experiment.AlExperiment
is a class which has encapsulated various tools and implemented the main loop of active learning.
Note that, AlExperiment only support the most commonly used scenario - query all labels of an instance. You can run the experiments with only a few lines of codes by this class. All you need is to specify the various options, the query process will be run in multi-thread.
Here is an example usage of this class:
from sklearn.datasets import load_iris
from alipy.experiment.al_experiment import AlExperiment
X, y = load_iris(return_X_y=True)
al = AlExperiment(X, y, stopping_criteria='num_of_queries', stopping_value=50)
al.split_AL()
al.set_query_strategy(strategy="QueryInstanceUncertainty", measure='least_confident')
al.set_performance_metric('accuracy_score')
al.start_query(multi_thread=True)
al.plot_learning_curve()
In the following tutorial, we will first introduce some restrictions when using this class. Then, the commonly used methods are presented. Finally, we give some examples when using this class.
Restrictions
To run the experiment with only one class, we have to impose some restrictions to make sure the robustness of the code:
1. Model restrictions
- Your model object should accord scikit-learn api.
2. Custom query strategy
- If a custom query strategy (callable) is given, you should construct a class and implement
the
__init__(self, X=None, y=None, **kwargs)
and
select(self, label_index, unlabel_index, batch_size=1, **kwargs)
methods. Additional parameters in kwargs should be static.
Initialzation & Functions
You can create an
AlExperiment
object by:
from sklearn.datasets import load_iris
from alipy.experiment import AlExperiment
X, y = load_iris(return_X_y=True)
al = AlExperiment(X, y, model=None, performance_metric='accuracy_score',
stopping_criteria='num_of_queries', stopping_value=50, batch_size=1)
- The
model
paramter is the classification model object which should accord the
scikit-learn
api. (implement
fit()
,
predict()
, and optionally
predict_proba()
functions according to your selected query strategy). If None is passed, it will use the default model which is the LogisticRegression model implemented by scikit-learn.
For the other optional parameters, please see the api reference of AlExperiment .
Data split
- You can set the existed data split indexes by
set_data_split(train_idx, test_idx, label_idx, unlabel_idx)
.
Or generate a new split by built-in function
split_Al()
.
e.g.,
al.split_AL(test_ratio=0.3, initial_label_rate=0.05, split_count=10, all_class=True)
.
For the usage of
split_Al
, please refer to the cognominal function in
alipy.ToolBox
.
Set query strategy
- ALiPy already implemented various classical and state-of-the-art query strategies.
You can use these query strategies by simply pass the name to
set_query_strategy()
function.
The list of available strategy names are
['QueryInstanceQBC', 'QueryInstanceUncertainty', 'QueryRandom', 'QureyExpectedErrorReduction', 'QueryInstanceGraphDensity', 'QueryInstanceQUIRE', 'QueryInstanceBMDR', 'QueryInstanceSPAL', 'QueryInstanceLAL']
.
Note that, the GraphDensity and QUIRE method need additional parameters, please refer to the tutorial for
query strategy
.
- You can also use your own query strategy by passing a class object implemented by your own.
Note that, your class should satisfy the constraints we introduced above.
class my_qs_class:
def __init__(self, X=None, y=None, **kwargs):
pass
def select(self, label_index, unlabel_index, batch_size=1, **kwargs):
"""Select instances to query."""
pass
al.set_query_strategy(strategy=my_qs_class(), **kwargs)
Set performance metric
- ALiPy already implemented many classical performance metrics. You can set the metric for experiment
by using
al.set_performance_metric(performance_metric='accuracy_score')
.
The list of available metric names are
['accuracy_score', 'roc_auc_score', 'get_fps_tps_thresholds', 'hamming_loss','one_error', 'coverage_error',
'label_ranking_loss', 'label_ranking_average_precision_score', 'zero_one_loss']
.
Start query
- After data split, setting query stategy, setting performance metric, you can start your experiment by using
al.start_query(multi_thread=True, **kwargs)
. The k-fold active learning experiments will run in multi-thread by default. The
kwargs
are the parameters used in
aceThreading
and
StateIO
init. If the
kwargs
is None, they will be initialized in the default way.
Get experiment result
- After the query process finish, you can get the results which
is a list of k
StateIO
object for k-fold experiment by
al.get_experiment_result()
.
Or you also can plot the learning curve of the k-fold experiment by
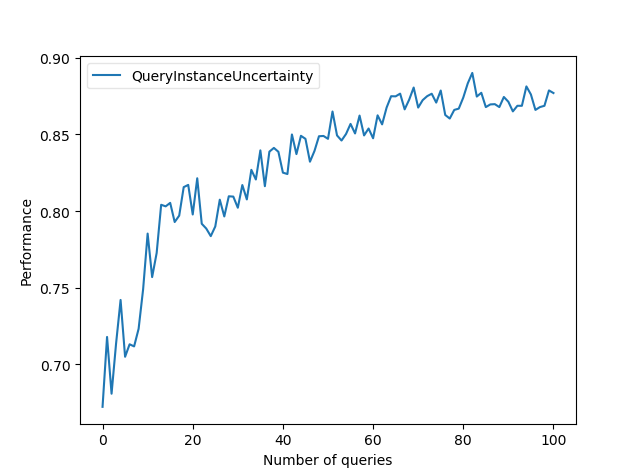
al.plot_learning_curve(title=None)
.
Examples
Preparation before strating query
from sklearn.datasets import load_iris
from alipy.experiment.al_experiment import AlExperiment
X, y = load_iris(return_X_y=True)
al = AlExperiment(X, y, stopping_criteria='num_of_queries', stopping_value=50,)
al.split_AL()
al.set_query_strategy(strategy="QueryInstanceUncertainty", measure='least_confident')
al.set_performance_metric('accuracy_score')
Start the query
Query in multi-thread
al.start_query(multi_thread=True)
or query sequentially
al.start_query(multi_thread=False)
Plot the result of the experiment
al.plot_learning_curve()